XMHell: Handling 38GB of UTF-16 XML with Rust
2020-05-11
A couple weekends ago, I found myself with the desire to fetch oil and gas production data for a specific county in New Mexico from the New Mexico Oil Conservation Division (OCD).
Fortunately, the OCD provides access to historical well production via an FTP server. I worked out that I needed to download /Public/OCD/OCD Interface v1.1/volumes/wcproduction/wcproduction.zip… and then my fortune ran out.
The first thing I noticed was the file size. The OCD doesn’t seem to provide a way to query a limited time- or area-based subset of production history data, so we’re stuck with a single zip file for “all of New Mexico since the dawn of time”1. The result is a whopping 712MB ZIP file.
Here’s where I knew I was in trouble: the only thing inside was a single 38 GB file called wcproduction.xml.
“XML is like violence: when it fails, apply more”
XML—the “extensible markup language”. Along with Java’s AbstractBeanFactoryTemplateFactorys, and the entirety of Geocities, XML epitomizes the excesses of the late 90s and early 2000s computing culture.
No two parsers can ever quite seem to agree on the details, and the verbosity quotient is such that an attempt to “print source” for the average “XHTML” web site circa 2001 would be likely to completely deforest the Amazon. The one thing that can be said in its favor is that it can indeed be used to somewhat faithfully represent a tree (the in-memory hierarchical structure, not the thing we just killed millions of).
Enough griping, though: the “XML everywhere” wave has long subsided. We’ve got to figure out how to deal with what it left behind. While it’s the most common approach to parsing XML, it’s also clear that loading the entire file into memory is unlikely to work: the workstation I’m writing this on only has 32GB of RAM. Additionally, it doesn’t make sense to build a syntax tree for the entire document when we are only interested in a small subset of the data. The XML world refers to this—here, unworkable—approach as a “DOM parser”, but it’s just the common case of parsing for any formal language—we incrementally construct an in-memory representation (that is, a syntax tree) of an entire document. It works well when we need the entire result and the in-memory representation fits comfortably within our resource budget: for instance, when compiling computer programs from source code, or rendering a web page from HTML.
Instead, we’ll use a streaming approach (the XML folks call this “SAX”, for reasons I didn’t care enough to research). In this approach, we’ll parse the document incrementally and receive results via an event-based API. This will let us only handle the data we care about, and minimize the amount we need to keep in memory at once.
For good performance on this “huge” data set, and to leverage an easily-accessible ecosystem of libraries which includes both streaming ZIP archive handling and high-performance streaming XML parsers, we’ll write a data extraction program in the Rust programming language.
(Re)Write It In Rust

I’m not going to belabor the reasons Rust is exciting here. It’s a statically-typed, compiled language with a nice mix of performance and control, expressiveness, and safety. I find it to be a nice choice for the sorts of “systems programming” tasks in which I might also use C or C++, but the build tools and package management system (Cargo) also make it a viable choice for these sorts of “script-like” programs, especially when performance may be an issue.
Let’s begin by creating a new Rust project using Cargo. We want a program (binary), not a library:
$ cargo new ocd_production --binThat’ll create a new directory ocd_production containing a Rust project. Inside we have a “hello world” program in src/main.rs and a specification for the project in Cargo.toml. The directory is also a git repository, which is handy.
There’s no sense in unpacking the ZIP file when we can stream our XML file out of it using the zip library. Let’s begin by just previewing the text of the XML file.
We’ll add zip to our Cargo.toml:
[package]
name = "ocd_production"
version = "0.1.0"
authors = ["Derrick W. Turk <dwt@terminusdatascience.com>"]
edition = "2018"
[dependencies]
zip = "0.5.5"A caveat before we begin: this is going to be “script” quality code. My goal is to process one file quickly and reliably, not to build a reusable library or produce “production-ready” code. As such, this code is going to skip some “best practices”: everything will be in one long main.rs file, and error handling will be oriented toward catching error conditions and aborting the program rather than toward error recovery or human-friendly error messages.
With that in mind, let’s write a short program in src/main.rs to take a ZIP file path as a command-line argument, and stream a few KB at a time from the file contained inside:
use std::{
env,
error::Error,
fs::File,
io::Read,
str,
};
use zip::ZipArchive;
const BUF_SIZE: usize = 4096; // 4kb at once
fn main() -> Result<(), Box<dyn Error>> {
let path = env::args().nth(1).ok_or("no filename provided")?;
let zipfile = File::open(path)?;
let mut zip = ZipArchive::new(zipfile)?;
if zip.len() != 1 {
Err("expected one file in zip archive")?;
}
let mut xmlfile = zip.by_index(0)?;
println!("file is {}, size {} bytes", xmlfile.name(), xmlfile.size());
let mut buf = [0u8; BUF_SIZE];
loop {
if xmlfile.read(&mut buf[..])? == 0 {
break;
}
println!("read chunk: {}", str::from_utf8(&buf[..])?);
}
Ok(())
}We’ll compile in “release mode” (that is, with optimizations enabled) and run against the ZIP file:
$ cargo run --release wc_production.zip
file is wcproduction.xml, size 38535541060 bytes
Error: Utf8Error { valid_up_to: 0, error_len: Some(1) }
That’s discouraging.
Only 90s Kids Will Remember This File Encoding
Like many “modern” languages, Rust’s standard string type is a UTF-8 encoded Unicode string. This is the right answer for a lot of good reasons, but it’s only become popular in recent years.
In this case, we’ve clearly encountered some text which is not encoded in UTF-8. In fact, we’ve hit an invalid byte as the very first byte. Let’s look at raw bytes, rather than Rust strings, so that we can see what’s going on. We’ll edit src/main.rs:
use std::{
env,
error::Error,
fs::File,
io::Read,
str,
};
use zip::ZipArchive;
const BUF_SIZE: usize = 4096; // 4kb at once
fn main() -> Result<(), Box<dyn Error>> {
let path = env::args().nth(1).ok_or("no filename provided")?;
let zipfile = File::open(path)?;
let mut zip = ZipArchive::new(zipfile)?;
if zip.len() != 1 {
Err("expected one file in zip archive")?;
}
let mut xmlfile = zip.by_index(0)?;
println!("file is {}, size {} bytes", xmlfile.name(), xmlfile.size());
let mut buf = [0u8; BUF_SIZE];
loop {
if xmlfile.read(&mut buf[..])? == 0 {
break;
}
println!("read chunk: {:?}", &buf[..]);
// we'll just dump the first chunk so we can see what's going on
break;
}
Ok(())
}
file is wcproduction.xml, size 38535541060 bytes
read chunk: [255, 254, 60, 0, 114, 0, 111, 0, 111, 0, 116, 0, 32, 0, 120, 0, 109, 0, 108, 0, 110, 0, 115, 0, 58, 0, 120, 0, 115, 0, 105, 0, 61, 0, 34, 0, 104, 0, 116, 0, 116, 0, 112, 0, 58, 0, 47, 0, 47, 0, 119, 0, 119, 0, 119, 0, 46, 0, 119, 0, 51, 0, 46, 0, 111, 0, 114, 0, 103, 0, 47, 0, 50, 0, 48, 0, 48, 0, 49, 0, 47, 0, 88, 0, 77, 0, 76, 0, 83, 0, 99, 0, 104, 0, 101, 0, 109, 0, 97, 0, 45, 0, 105, 0, 110, 0, 115, 0, 116, 0, 97, 0, 110, 0, 99, 0, 101, 0, 34, 0, 62, 0, 60, 0, 120, 0, 115, 0, 100, 0, 58, 0, 115, 0, 99, 0, 104, 0, 101, 0, 109, 0, 97, 0, 32, 0, 116, 0, 97, 0, 114, 0, 103, 0, 101, 0, 116, 0, 78, 0, 97, 0, ...
At this point, recovering Windows programmers and Java programmers are wincing in sympathy. Two things immediately stand out: first, we’ve got a series of bytes alternating between the printable ASCII range and zero, and second, we open with 0xFF 0xFE—that’s a BOM. We’re dealing with UTF-16 in little-endian byte order.
If you want the short version of how we got here, I suggest reading Chapter 11 of the Book of Genesis.
The slightly longer version goes like this: in the late 80s, some forward-thinking folks began thinking seriously about the fact that non-Americans were using computers. In fact, some of the world’s computer users weren’t even Europeans, who could usually get away with smuggling some funny accented Latin characters into that “unused” eighth bit of ASCII. Of course, the non-Latin alphabet folks were doing just fine on their own: they had their own character sets and encodings.
But wouldn’t it be nice if we could all share one universal character set? Some sort of… “Uni”versal “code”? Surely, they reasoned, the Chinese/Japanese/Korean (CJK) character sets, the Latin alphabet, the Cyrillic alphabet, and anything else of interest could all be encoded into a shared 16-bit range. 65,536 characters should be enough for all the world’s languages! We’d just decide that the new “character type” was a 16-bit integer instead of an 8-bit integer; strings could still be arrays of these characters, and doubling the storage required for existing ASCII text was an acceptable price to pay for global harmony. Big names committed to this new “Universal Character Set” (UCS-2): Microsoft rebuilt Windows’ string handling to use strings of two-byte UCS-2 “wide characters”, and the hot new Java programming language made the same decision.
As you can imagine, 65,536 characters did not turn out to be nearly enough for all the world’s languages—much less the wave of weird 👩👩👦👦 characters 💯 yet to 🔜 appear. Unicode ended up adopting a 32-bit address space, supporting over 4 billion characters. We’re unlikely to fill that any time soon, even given the breathtaking pace of emoji creation.
However, it also seemed unattractive to commit to an encoding which used fixed-width 32-bit characters. Encoding and decoding would be simple, but for the (still very common) case of plain ASCII text, we’d waste 3 bytes out of every 4. The solution was a “patch” in the form of the UTF-16 encoding, which used 16-bit “characters” like UCS-2, but provided an escape mechanism to encode characters outside the Basic Multilingual Plane as two-character “surrogate pairs”.
This let the Windows and Java people patch up their systems, but it’s sort of unsatisfying: once we’ve accepted the need for a variable-width encoding, why are we still wasting two bytes per character even for the Latin alphabet? This line of reasoning led directly to UTF-82, which uses ordinary one-byte characters in a variable-width encoding scheme to faithfully represent all of Unicode while preserving compatibility with ASCII.
Returning from our digression into computational Babel, we spot the other issue with “wide characters” which we’ve directly encountered in our XML file. Our modern computer architectures are “byte-oriented”: we’ve achieved a sort of rough consensus that everything should be able to work on atomic units of 8 bits. However, almost all interesting quantities are larger: we work with 64-bit (8 byte) addresses, 16-bit (2 byte) UCS-2 characters, and so forth. How shall we represent these inside a world of sequentially-addressed bytes? We have two main choices: least-significant byte first (“little-endian”) or most-significant byte first (“big-endian”). Different CPU architectures made different choices, and so when we share UCS-2 or UTF-16 text we need a way to tell which byte order the text was encoded with. That’s the purpose of the BOM we saw at the beginning of our file: since the Unicode-mandated value of 0xFEFF has appeared in our file as 0xFF 0xFE, we know that this file was encoded with a little-endian byte order.
Very fortunately for us, we can use a library to take care of all of this for us. The encoding_rs and encoding_rs_io libraries will let us translate from UTF-16 to UTF-8 on the fly, which will let us send ordinary Rust strings into our XML parser.
We will update Cargo.toml:
[package]
name = "ocd_production"
version = "0.1.0"
authors = ["Derrick W. Turk <dwt@terminusdatascience.com>"]
edition = "2018"
[dependencies]
encoding_rs = "0.8.22"
encoding_rs_io = "0.1.7"
zip = "0.5.5"And then src/main.rs:
use std::{
env,
error::Error,
fs::File,
io::Read,
str,
};
use zip::ZipArchive;
use encoding_rs_io::DecodeReaderBytes;
const BUF_SIZE: usize = 4096; // 4kb at once
fn main() -> Result<(), Box<dyn Error>> {
let path = env::args().nth(1).ok_or("no filename provided")?;
let zipfile = File::open(path)?;
let mut zip = ZipArchive::new(zipfile)?;
if zip.len() != 1 {
Err("expected one file in zip archive")?;
}
let xmlfile = zip.by_index(0)?;
println!("file is {}, size {} bytes", xmlfile.name(), xmlfile.size());
let mut xmlfile = DecodeReaderBytes::new(xmlfile);
let mut buf = [0u8; BUF_SIZE];
loop {
if xmlfile.read(&mut buf[..])? == 0 {
break;
}
println!("read chunk: {}", str::from_utf8(&buf[..])?);
// again, just print the first chunk
break;
}
Ok(())
}
file is wcproduction.xml, size 38535541060 bytes
read chunk: <root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"><xsd:schema targetNamespace="urn:schemas-microsoft-com:sql:SqlRowSet1" xmlns:schema="urn:schemas-microsoft-com:sql:SqlRowSet1" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:sqltypes="http://schemas.microsoft.com/sqlserver/2004/sqltypes" elementFormDefault="qualified"><xsd:import namespace="http://schemas.microsoft.com/sqlserver/2004/sqltypes" schemaLocation="http://schemas.microsoft.com/sqlserver/2004/sqltypes/sqltypes.xsd"/><xsd:element name="wcproduction"><xsd:complexType><xsd:sequence><xsd:element name="api_st_cde" type="sqltypes:smallint" nillable="1"/><xsd:element name="api_cnty_cde" type="sqltypes:smallint" nillable="1"/><xsd:element name="api_well_idn" type="sqltypes:int" nillable="1"/><xsd:element name="pool_idn" type="sqltypes:int" nillable="1"/><xsd:element name="prodn_mth" type="sqltypes:smallint" nillable="1"/><xsd:element name="prodn_yr" type="sqltypes:int" nillable="1"/><xsd:element name="ogrid_cde" type="sqltypes:int" nillable="1"/><xsd:element name="prd_knd_cde" nillable="1"><xsd:simpleType><xsd:restriction base="sqltypes:char" sqltypes:localeId="1033" sqltypes:sqlCompareOptions="IgnoreCase IgnoreKanaType IgnoreWidth" sqltypes:sqlSortId="52"><xsd:maxLength value="2"/></xsd:restriction></xsd:simpleType></xsd:element><xsd:element name="eff_dte" type="sqltypes:datetime" nillable="1"/><xsd:element name="amend_ind" nillable="1"><xsd:simpleType><xsd:restriction base="sqltypes:char" sqltypes:localeId="1033" sqltypes:sqlCompareOptions="IgnoreCase IgnoreKanaType IgnoreWidth" sqltypes:sqlSortId="52"><xsd:maxLength value="1"/></xsd:restriction></xsd:simpleType></xsd:element><xsd:element name="c115_wc_stat_cde" nillable="1"><xsd:simpleType><xsd:restriction base="sqltypes:char" sqltypes:localeId="1033" sqltypes:sqlCompareOptions="IgnoreCase IgnoreKanaType IgnoreWidth" sqltypes:sqlSortId="52"><xsd:maxLength value="1"/></xsd:restriction></xsd:simpleType></xsd:element><xsd:element name="prod_amt" type="sqltypes:int" nillable="1"/><xsd:element name="prodn_day_num" type="sqltypes:smallint" nillable="1"/><xsd:element name="mod_dte" type="sqltypes:datetime" nillable="1"/></xsd:sequence></xsd:complexType></xsd:element></xsd:schema><wcproduction xmlns="urn:schemas-microsoft-com:sql:SqlRowSet1"><api_st_cde>30</api_st_cde><api_cnty_cde>5</api_cnty_cde><api_well_idn>20178</api_well_idn><pool_idn>10540</pool_idn><prodn_mth>7</prodn_mth><prodn_yr>1973</prodn_yr><ogrid_cde>12437</ogrid_cde><prd_knd_cde>G </prd_knd_cde><eff_dte>1973-07-31T00:00:00</eff_dte><amend_ind>N</amend_ind><c115_wc_stat_cde>F</c115_wc_stat_cde><prod_amt>53612</prod_amt><prodn_day_num>99</prodn_day_num><mod_dte>2015-04-07T07:31:00.173</mod_dte></wcproduction><wcproduction xmlns="urn:schemas-microsoft-com:sql:SqlRowSet1"><api_st_cde>30</api_st_cde><api_cnty_cde>5</api_cnty_cde><api_well_idn>20178</api_well_idn><pool_idn>10540</pool_idn><prodn_mth>7</prodn_mth><prodn_yr>1973</prodn_yr><ogrid_cde>12437</ogrid_cde><prd_knd_cde>O </prd_knd_cde><eff_dte>1973-07-31T00:00:00</eff_dte><amend_ind>N</amend_ind><c115_wc_stat_cde>P</c115_wc_stat_cde><prod_amt>75262</prod_amt><prodn_day_num>99</prodn_day_num><mod_dte>2015-04-07T07:31:00.173</mod_dte></wcproduction><wcproduction xmlns="urn:schemas-microsoft-com:sql:SqlRowSet1"><api_st_cde>30</api_st_cde><api_cnty_cde>5</api_cnty_cde><api_well_idn>20178</api_well_idn><pool_idn>10540</pool_idn><prodn_mth>7</prodn_mth><prodn_yr>1973</prodn_yr><ogrid_cde>12437</ogrid_cde><prd_knd_cde>W </prd_knd_cde><eff_dte>1973-07-31T00:00:00</eff_dte><amend_ind>N</amend_ind><c115_wc_stat_cde>P</c115_wc_stat_cde><prod_amt>25509</prod_amt><prodn_day_num>99</prodn_day_num><mod_dte>2015-04-07T07:31:00.173</mod_dte></wcproduction><wcproduction xmlns="urn:schemas-microsoft-com:sql:SqlRowSet1"><api_st_cde>30</api_st_cde><api_cnty_cde>15</api_cnty_cde><api_well_idn>645</api_well_idn><pool_idn>51300</pool_idn><prodn_mth>10</prodn_mth><prodn_yr>1973</prodn_yr><ogrid_cde>19958</ogrid_cde><prd_knd_cde>O </prd_knd_cde><eff_dte>1973-10-31T00:00:00</eff_dte><amend_ind>N</amend_ind>
Seeing Like a State Machine
OK, so that’s obviously some fairly horrible XML auto-generated by Microsoft SQL Server. If we squint, we can see that the structure is a sequence of <wcproduction> elements containing nested elements for the pieces of data we care about: well API numbers, production volumes, and so on.
We’re going to use a streaming approach to parse this due to the huge file size. After some very superficial research, I decided to go with the quick-xml library because it had good documentation, good performance, and roughly the API I was looking for. The first step is to make sure we can stream “events” (for example, “beginning of element”) from our XML file.
We make one final update to Cargo.toml:
[package]
name = "ocd_production"
version = "0.1.0"
authors = ["Derrick W. Turk <dwt@terminusdatascience.com>"]
edition = "2018"
[dependencies]
encoding_rs = "0.8.22"
encoding_rs_io = "0.1.7"
quick-xml = "0.18.1"
zip = "0.5.5"In src/main.rs we replace our chunk-at-a-time println with a pattern match on events generated by the quick-xml parser:
use std::{
env,
error::Error,
fs::File,
io::BufReader,
str,
};
use zip::ZipArchive;
use encoding_rs_io::DecodeReaderBytes;
use quick_xml::{
events::Event,
Reader,
};
const BUF_SIZE: usize = 4096; // 4kb at once
fn main() -> Result<(), Box<dyn Error>> {
let path = env::args().nth(1).ok_or("no filename provided")?;
let zipfile = File::open(path)?;
let mut zip = ZipArchive::new(zipfile)?;
if zip.len() != 1 {
Err("expected one file in zip archive")?;
}
let xmlfile = zip.by_index(0)?;
println!("file is {}, size {} bytes", xmlfile.name(), xmlfile.size());
let xmlfile = BufReader::new(DecodeReaderBytes::new(xmlfile));
let mut xmlfile = Reader::from_reader(xmlfile);
let mut buf = Vec::with_capacity(BUF_SIZE);
loop {
match xmlfile.read_event(&mut buf)? {
Event::Start(e) => {
println!("start {}", str::from_utf8(e.local_name())?);
},
Event::End(e) => {
println!("end {}", str::from_utf8(e.local_name())?);
},
Event::Text(e) => {
println!("text: {}", str::from_utf8(&e.unescaped()?)?);
},
Event::Eof => break,
_ => { },
};
buf.clear();
}
Ok(())
}
file is wcproduction.xml, size 38535541060 bytes
...
start wcproduction
text:
start api_st_cde
text: 30
end api_st_cde
text:
start api_cnty_cde
text: 5
end api_cnty_cde
text:
start api_well_idn
text: 20178
end api_well_idn
text:
start pool_idn
text: 10540
end pool_idn
text:
start prodn_mth
text: 7
end prodn_mth
text:
start prodn_yr
text: 1973
end prodn_yr
text:
start ogrid_cde
text: 12437
end ogrid_cde
text:
start prd_knd_cde
text: G
end prd_knd_cde
text:
start eff_dte
text: 1973-07-31T00:00:00
end eff_dte
text:
start amend_ind
text: N
end amend_ind
text:
start c115_wc_stat_cde
text: F
end c115_wc_stat_cde
text:
start prod_amt
text: 53612
end prod_amt
text:
start prodn_day_num
text: 99
end prodn_day_num
text:
start mod_dte
text: 2015-04-07T07:31:00.173
end mod_dte
text:
end wcproduction
...
At this point we can clearly see the structure of each production record. To turn these incremental events into an in-memory structure containing the production data we care about, we’ll build a simple state machine.
Consider the “shape” of each <wcproduction> element. At any point in the file, our parser may be in any of the following states:
- between records (including the span before the first
<wcproduction>element)
- reading a production record, but before we have a full API number
- reading the state code for an API number
- reading the county code for an API number
- reading the well identifier for an API number
- reading a production record, with the API number now known
- skipping the remainder of a production record, due to its API number
- reading the month of production
- reading the year of production
- reading the fluid type produced (oil, gas, or water)
- reading the production volume
In Rust, we’ll encode this state into an enum type, and our state machine parser as a struct type:
#[derive(Copy, Clone, Debug)]
enum ParserState {
Between,
ProductionNeedAPI,
ReadAPIState,
ReadAPICounty,
ReadAPIWell,
ProductionHaveAPI,
ProductionSkip,
ReadMonth,
ReadYear,
ReadPhase,
ReadVolume,
}
struct WellProductionParser<'a> {
state: ParserState,
phase: Phase,
production: HashMap<WellAPI, HashMap<Date, WellProduction>>,
current_api: WellAPI,
current_date: Date,
api_predicate: Option<&'a dyn Fn(WellAPI) -> bool>,
}The final result is accumulated into the production member, as a nested hash map which lets us look up production first by well API number, then by date. The parser can optionally hold a predicate function (as a trait object) which it will use to decide whether to process or skip each record based on the API number (for example, to filter to a single county).
Let’s begin by sketching a “transition diagram” for our state machine. We’ll use arrows to indicate the possible state transitions, and label them with the events which trigger them: 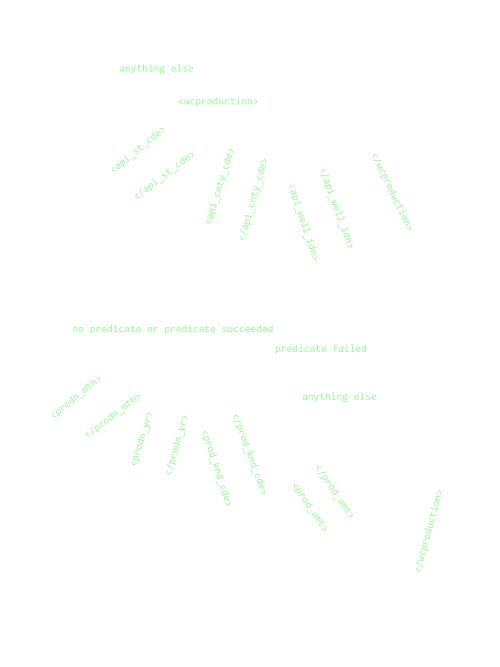
In Rust, we can implement this as a function on our WellProductionParser struct, which consumes an Event from the XML parser, takes the appropriate action for the current state, and updates the state. Here’s an abbreviated version:
impl<'a> WellProductionParser<'a> {
...
pub fn process(&mut self, ev: Event) -> Result<(), Box<dyn Error>> {
self.state = match self.state {
ParserState::Between => {
match ev {
Event::Start(e) if e.local_name() == b"wcproduction" =>
ParserState::ProductionNeedAPI,
_ => ParserState::Between,
}
},
ParserState::ProductionNeedAPI => {
match ev {
Event::Start(e) => match e.local_name() {
b"api_st_cde" => ParserState::ReadAPIState,
b"api_cnty_cde" => ParserState::ReadAPICounty,
b"api_well_idn" => ParserState::ReadAPIWell,
_ => ParserState::ProductionNeedAPI,
},
_ => ParserState::ProductionNeedAPI,
}
},
...
};
Ok(())
}
}With the state-machine based parser up and running, the last step is simply to provide tabular output for the collected data. We’ll write tab-separated text, which can be easily copied and pasted into a spreadsheet, or processed by other programs. We’ll also sort the production for each well by date—the XML is not necessarily in order.
fn write_table(w: &mut impl Write,
production: &HashMap<WellAPI, HashMap<Date, WellProduction>>
) -> io::Result<()> {
write!(w, "api\tyear\tmonth\toil\tgas\twater\n")?;
for (api, by_date) in production {
let mut dates: Vec<_> = by_date.keys().collect();
dates.sort();
for date in dates {
write!(w, "{}\t{}\t{}", api, date.year, date.month)?;
let vols = &by_date[date];
if let Some(oil) = vols.oil {
write!(w, "\t{}", oil)?;
} else {
write!(w, "\t")?;
}
if let Some(gas) = vols.gas {
write!(w, "\t{}", gas)?;
} else {
write!(w, "\t")?;
}
if let Some(water) = vols.water {
write!(w, "\t{}\n", water)?;
} else {
write!(w, "\t\n")?;
}
}
}
Ok(())
}Our final main looks like this, now applying a predicate which filters using API numbers to select only wells in Eddy County:
fn main() -> Result<(), Box<dyn Error>> {
let path = env::args().nth(1).ok_or("no filename provided")?;
let zipfile = File::open(path)?;
let mut zip = ZipArchive::new(zipfile)?;
if zip.len() != 1 {
Err("expected one file in zip archive")?;
}
let xmlfile = zip.by_index(0)?;
let xmlfile = BufReader::new(DecodeReaderBytes::new(xmlfile));
let mut xmlfile = Reader::from_reader(xmlfile);
let mut prodparser = WellProductionParser::with_predicate(
&|api: WellAPI| api.county == EDDY_COUNTY);
let mut buf = Vec::with_capacity(BUF_SIZE);
loop {
match xmlfile.read_event(&mut buf)? {
Event::Eof => break,
ev => prodparser.process(ev)?,
};
buf.clear();
}
let prod = prodparser.finish();
write_table(&mut io::stdout(), &prod)?;
Ok(())
}On my “workstation”, this runs in a couple of minutes and extracts a 92MB tab-separated file from the ZIP archive. Not bad!
The entire source code for this project can be found on GitHub at https://github.com/derrickturk/ocd_production. Please feel free to adapt it to your own purposes.